


By far the costliest and most time-consuming aspect of investigations, inquiries, and legal matters...
Have you ever considered assigning a task to someone else but then thought ‘It would be quicker to do it myself’ or ‘They won’t do it as well as I could’? If so, you’re not alone – lots of people are bad delegators. While artificial intelligence is currently getting a lot of attention and being proposed as a solution to all kinds of problems, people often raise the same objections about using AI to classify items in investigative data sets.
Objection 1: it would be quicker to do it myself
Our white paper, Continuous active learning: the EDT approach, discusses how you can use machine learning to automatically classify items in a data set.
In a previous blog post, I talked about how the first generation of technology assisted review (TAR) or predictive coding was helpful but cumbersome, in that it required a large control set (many thousands) of manually reviewed items and a multi-stage process of training and fine-tuning the predictive model on those items.
In this case, the bad delegator’s argument is often correct. Using TAR, it takes time and effort to teach a computer to classify items as accurately as a human. That’s why people typically use TAR for larger data sets, because the time saved by applying the model is more than the time it takes to classify items and train the model.
A major advantage of second-generation technology, often called continuous active learning (CAL), is the time it takes to start getting results – even with small data sets.
 Tell the computer who's boss, even if it will do a better and faster job than you could. Photo by Mizuno K
Tell the computer who's boss, even if it will do a better and faster job than you could. Photo by Mizuno K
In our white paper, we conducted a series of experiments using EDT’s implementation of CAL. We started with a data set of just under 10,000 items that we knew contained half relevant items and half irrelevant ones.
The first batch of 100 items we reviewed – which we used to train the CAL model – contained about half relevant ones (50% prevalence), as you would expect. If half of all the items are relevant, a random sample of those items would also be around 50% relevant. Without CAL, each subsequent batch would be another random sample, so you would again expect it to contain around 50% relevant items until you found most of them. But what happens with CAL?
You might think it would take at least a few rounds for the CAL algorithm to learn from the human coding decisions and gradually grow the batch prevalence figure above 50%.
But in our experiment, the next batch of 100 items contained more than 95% relevant ones, and so did the next 20 or so rounds. This is because the CAL model had already learned to distinguish between relevant and irrelevant items after just one batch of reviewing.
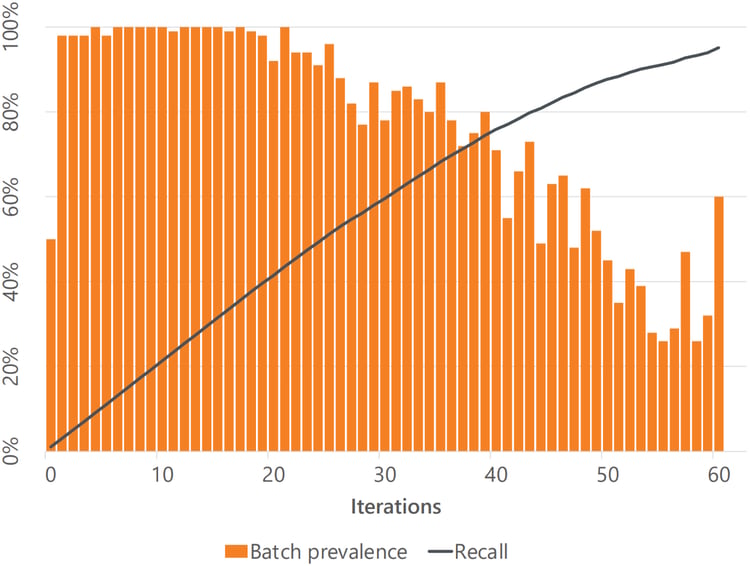
A series of review batches using CAL, with a starting prevalence of 50%.
And in fact, the batch prevalence only started to dip below 80% when we had already found more than half of the relevant items in the data set (the recall was over 50%). By this stage, having found most of the relevant items, additional relevant ones became increasingly hard to come by.
Let’s say our goal was to find 80% of the relevant items – a typical benchmark in regulatory and legal investigations. With simple random sampling, finding around 50 relevant items per review batch, it would take 78 review batches, or thereabouts, to reach that mark. But using CAL, it only took 40 rounds of review. That’s almost twice as fast! Similarly, finding 95% of relevant items would take 98 rounds of review using random samples but only took 60 batches using CAL.
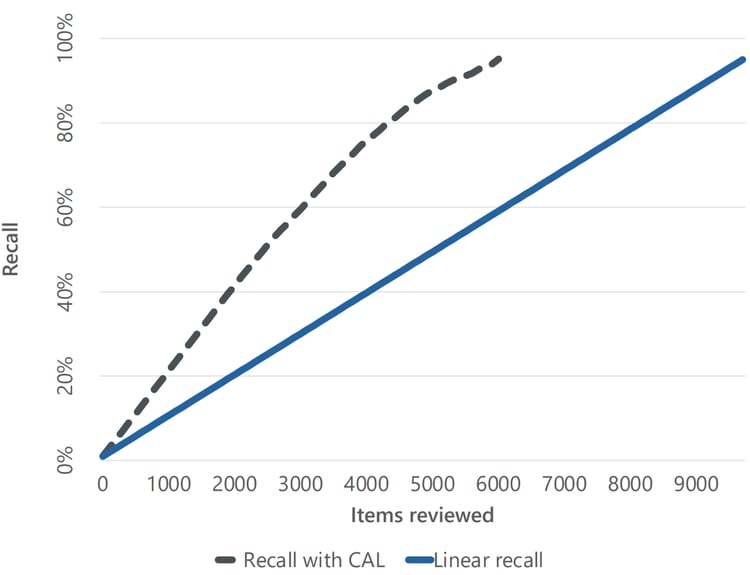
Comparing the number of review batches to find relevant items using CAL with using linear review (random samples) of the same data set.
You might be thinking, OK, that’s good when you have a data set that’s half relevant items and half not, but I deal with data sets where a much smaller proportion of the items is relevant.
We repeated the experiment with data sets that had prevalences of 29%, 17%, and 4%.
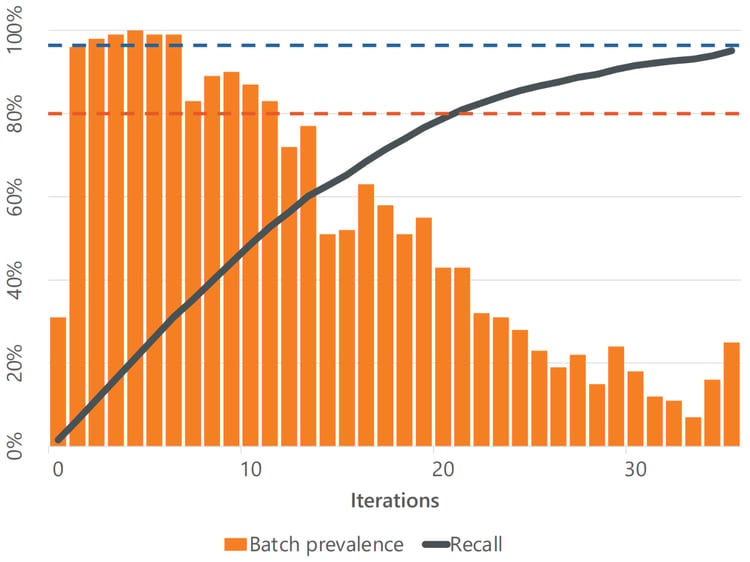
A series of review batches using CAL, with a starting prevalence of 29%.
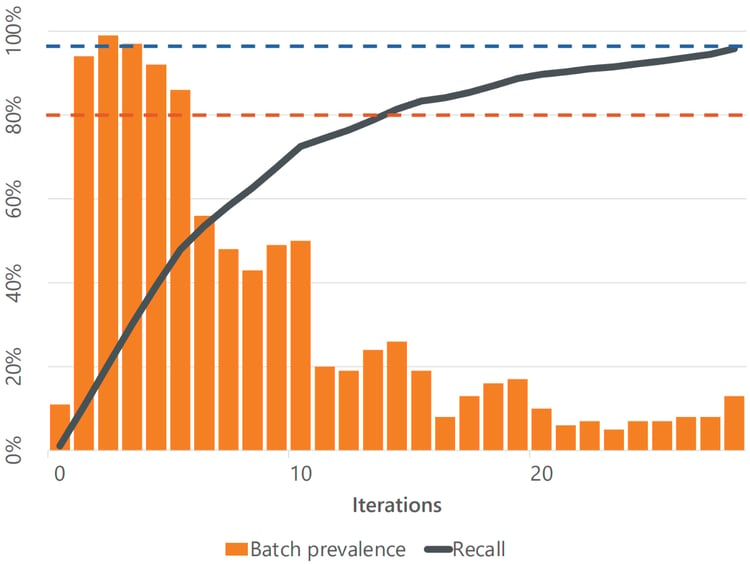
A series of review batches using CAL, with a starting prevalence of 17%.
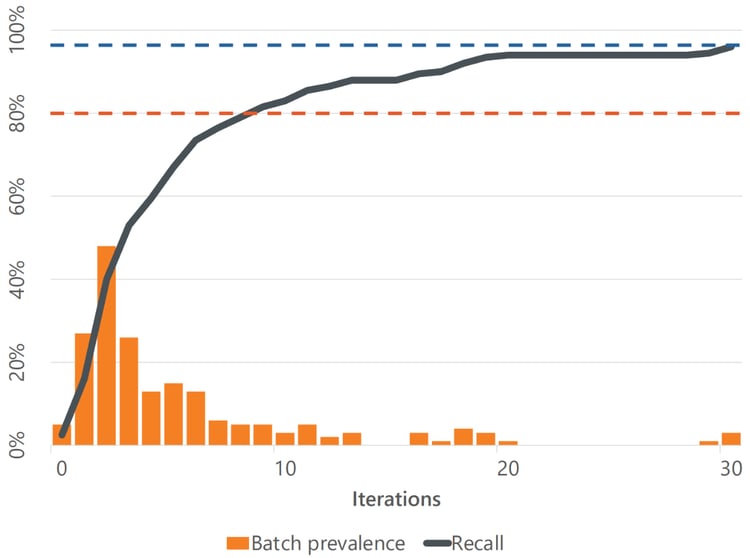
A series of review batches using CAL, with a starting prevalence of 4%.
In each case, using CAL meant the first review batches contained very high proportions of relevant items until we had found more than half of all the relevant items.
Objection 2: they won’t do it as well as I could
Now that I’ve answered your first objection – that it would take too long to teach the computer to classify items – perhaps we can also address the other one – that a computer won’t do as good a job as a human reviewer.
In fact, this objection was dealt with more than a decade ago in the first case to consider the legal applications of TAR, Da Silva Moore v. Publicis Groupe et al 11-civ-1279 (ALC). Magistrate Judge Andrew Peck noted that ‘statistics clearly show that computerized searches are at least as accurate, if not more so, than manual review’ (at pp 28-29).
Similarly, in Irish Bank Resolution Corporation Ltd v Quinn [2015] IEHC 175 in the High Court of Ireland, Fullham J said at [67], ‘If one were to assume that TAR will only be equally as effective, but no more effective, than a manual review, the fact remains that using TAR will still allow for a more expeditious and economical discovery process.’
Another factor to consider is that these legal opinions were discussing the use of first-generation TAR, where a computer model made decisions about which items were relevant or not. Using CAL, a human makes all those decisions; the AI model works in the background to make it easier and faster to find the relevant items.
See relevant items sooner
The conclusion is clear: using CAL means you’re much more likely to see relevant items earlier in your investigation, and dramatically reduce the time and cost of review. You can apply CAL to relatively small data sets and still save time. You can keep looking until you’ve found enough. The computer will do the job as accurately as a human could, or more accurately, only much faster. And you can apply CAL as easily as ticking a box in EDT’s Review Pools function, so why not give it a go?
If this sounds like it could help you complete investigations more efficiently, download the white paper today.


