


Have you ever considered assigning a task to someone else but then thought ‘It would be quicker to...
By far the costliest and most time-consuming aspect of investigations, inquiries, and legal matters is having human beings read and make decisions about documents, emails, and other items – such as deciding if they’re relevant to the case, legally privileged, or responsive to a production request.
Let’s say it takes you an average of five minutes to read each item and make that decision. And let’s say you have a modest 100,000 items. (Large legal and regulatory cases often contain tens of millions of items.) At 12 items per hour, that’s 8,333 hours. If you sat and reviewed items for 38 hours a week, 48 weeks a year, you’d be lucky to finish by mid-2028 (unless the tedium drove you to find another job first). Even with 10 people reviewing full time, it would take five and a half months to get through all those items.
That’s clearly untenable.
This is why investigators use all sorts of techniques – such as date ranges and keyword searches – to eliminate irrelevant items from their data sets. Machine learning provides a powerful and highly effective technique to help you get a manageable number of items for humans to read.

If your plans between now and 2028 involve something other than reading documents for an investigation, you need advanced technology. Photo by Andrea Piacquadio
How machine learning can help
We have become accustomed to spam filters that help us decide which emails we should ignore, and recommendation systems that help us decide what to buy, watch, read, or listen to next.
Many of these recommendation systems use machine learning algorithms, a form of artificial intelligence, to make predictions about which emails are likely to be spam or which products might interest us.
These algorithms are a type of supervised learning because they make predictions about future decisions based on previous decisions. For example, spam filters are typically trained using sample emails that a human being has categorised as ‘spam’ or ‘not spam’. These filters continue to learn as people flag their emails as spam (if they’re not automatically filtered) or not spam (if they’re filtered in error). Shopping and media sites recommend products and content according to preferences gleaned from observing previous and real-time activity – yours and everyone else’s.
When you’re reviewing digital evidence, you can use predictive models – trained using the decisions of human expert reviewers – to classify items. These algorithms are collectively called technology assisted review (TAR) or predictive coding.
The first generation of TAR was helpful but cumbersome, in that it required a multi-stage process of:
- Creating a control set of several thousand items, usually by random sampling, and manually coding them as responsive or not responsive
- Building and refining a predictive model until it could classify the items the same way as the human reviewers, to a required degree of accuracy
- Applying the model against the remainder of the collection to classify the remaining items.
CAL: the next generation
Our white paper, Continuous active learning: the EDT approach, examines the second generation of machine learning technologies for document review, one that has great potential to accelerate investigations and reduce the burden of linear review.
Continuous active learning (CAL) involves iteratively reviewing small batches of items and coding them as responsive or not, relevant or not, privileged or not, or any other binary decision you’re trying to evaluate. As you review each batch, CAL uses these codings to refine its machine learning model, so that reviewer input is quickly fed back into the predictive process and used to refine the rankings of the items yet to be reviewed. It then provides for review the next batch of items that it predicts are most relevant.
In this way, CAL allows reviewers to focus on reviewing the most relevant material as soon as possible. In addition, unlike predictive coding, the computer only makes decisions about which items to provide for review – a human being still decides how to code each item.
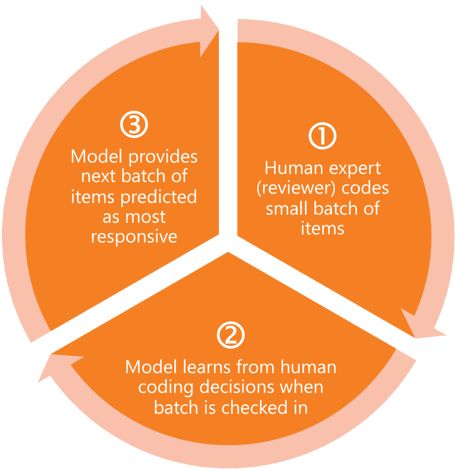
The iterative coding and prediction cycle of continuous active learning (CAL).
Download our white paper
How quickly does it work? As my next blog post shows, the answer is much sooner than you think! Or you can download the white paper today to get the whole story for yourself.


